MindBites
A B2B autoplay recommendation engine for podcast platforms, powered by patented hash-based clip identification and a reverse-LLM scoring architecture that runs zero AI calls at query time.
Most podcast platforms have an autoplay problem. When an episode ends, the next thing the listener hears is either silence, a host plug, or a recommendation pulled from a “you might also like” algorithm tuned for completion rate, not relevance. MindBites is the engine that fills that gap. It serves frame-accurate audio clips as a post-roll carousel inside existing podcast players (iHeart, Prisa, Triton-powered apps), turning the moment after an episode into a discovery surface without forcing publishers to rebuild their players.
The patent
The technical foundation is a SHA-256 hash-based clip identification system (US 11,947,584 B1, granted April 2024) that locates a clip inside a podcast episode even after the source audio has been re-encoded, ad-inserted, or partially re-uploaded by the publisher. The hash is computed at ingestion, the clip travels independently of the source file, and the player can resolve it back to the original episode regardless of CDN behavior. This is what makes the autoplay carousel work in the wild, where every podcast download serves a different ad pre-roll and the audio bytes are never the same twice.
The v2 architecture
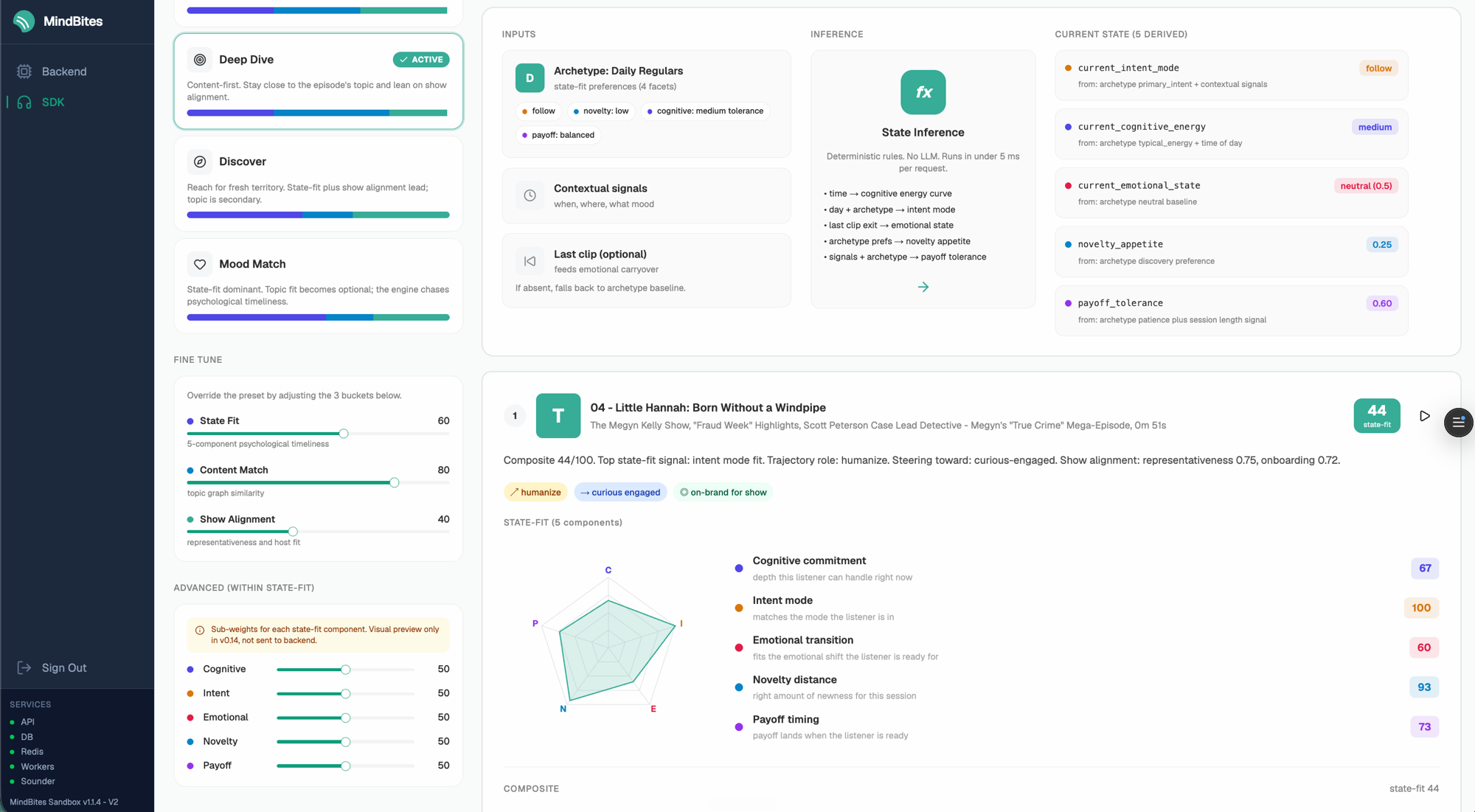
MindBites v2 is built on a reverse-LLM design. All the expensive AI work happens at ingestion: WhisperX (on GCP Cloud Run with NVIDIA L4 GPUs) produces word-level transcripts, Claude extracts 8 to 12 high-quality clips per episode and tags each one against 14 listener-facing facets plus 2 bridge scores, OpenAI generates embeddings, and FFmpeg slices the audio. The query path is the opposite. When a recommendation request comes in, there are zero LLM calls and zero embedding calls. A ListenerStateInference step composes a listener state from the active archetype, contextual signals, and the last clip played, then a four-stage funnel scores the full approved library: clip library → diversity filter → intent filter → state-fit scoring. The scorer is pure compute across three weighted axes (state-fit, content-fit, show-alignment) with per-card transparency: radar chart, trajectory-role chips, “why this clip” breakdown, and a visible rejected-candidates list. Sub-200ms p95 on a 5,000-clip pool.
Archetypes and trajectory chaining
Five archetypes (Deep Divers, Daily Regulars, Wind-Downers, Vibe Seekers, Curious Wanderers) span the state-fit space rather than approximating individual users. They are anchored to real podcasts in the catalog so the matching is grounded in actual content shape. When a listener plays a clip, the next request carries the played clip’s emotional_exit_state and good_successor_states, and the engine steers toward compatible next clips. Compare mode renders multiple archetypes side-by-side as stripes for publisher demos, with full transparency on why each clip ranks where it does.
The platform around it
The backend is FastAPI with Celery workers on Railway, a Supabase Postgres with pgvector and HNSW indexes for the embedding store, and a Next.js 15 admin frontend (shadcn/ui, Tailwind v4) that doubles as a publisher-facing playground. RSS scheduler polls feeds on configurable frequencies, ingests new episodes through the eight-step pipeline, handles dynamic ad insertion safely by persisting downloads once and reusing across steps, and dedups against Listen Notes and Sounder metadata. Production smoke tests run against live ingestion.
The wider context
MindBites is the venture work behind PodCrunch Inc. The reco engine is the centerpiece, but the surrounding ecosystem includes an embeddable JS player (Vue and React builds), an iHeart pilot integration, a React Native mobile app, and a parallel research track on a listener-owned identity layer (“MindBites Passport”) that would let publishers personalize without receiving user data. The current architectural focus is making the v2 engine production-ready for the autoplay use case while keeping the patent at the center of every integration path.